专业书籍
- C++ Primer Plus [2020.05-2020.06]
- C++语言的设计与演化 [2021.08.30-]
论文
推荐
- (KDD2021)Learning Elastic Embeddings for Customizing On-Device Recommenders(202108)
服务器通常有着固定的内存和性能,因此我们可以训练一个模型,找到能够内存和计算能力适配这个模型的机器即可。不同于在服务器上进行推荐,边缘计算的难点在于边缘设备的性能相差较大,智能设备的内存大小不一,不可能为每一个设备都训练一个模型。
由于隐私和网络延迟的原因,现在更倾向于在边缘设备而非云服务器上部署推荐服务。在边缘设备上构建推荐系统的常用做法是压缩嵌入表示。本文提出了一种轻量级训练范式,核心思想是为每个item构造一个弹性embedding,弹性embedding是自动搜索出的由一组embedding-block的拼接。提出了一种RULE(Recommendation with Universally Learned Elastic Embeddings)方法,为了增强embeding-block的表示,在学习embedding-block时迫使其趋向于多样化;然后设计了基于性能估计的渐进搜索方法,允许在任何内存限制下来学习有效的弹性embedding。
为了实现基于边缘计算的推荐系统,受限于边缘设备的内存大小,模型的参数数量以及embedding的维度需要有所限制,大部分工作都是基于潜在因子模型(LFM)来进行的,例如矩阵分解。主要思路是将每个user和item表示成embedding,然后通过相似度计算或者网络结构来计算两者的匹配得分,由于存在大量的类别特征,因此LFM模型的主要参数是embedding而非模型weights和biases。因此大多数工作都是压缩embedding的维度从而减小模型的大小。
早期研究采用离散哈希将实值嵌入转换为二进制,以两者的汉明距离来衡量user和item的相似性,由于转换过程中的信息丢失,使得二进制编码的表示效果极差,远不如普通的矩阵分解。
目前主要的两种方法是基于组合嵌入和多维嵌入的方法。组合嵌入只有少量的元嵌入表示,user和item则表示成元嵌入的不同组合,而多维嵌入允许每个嵌入表示在训练过程中的维度不一致,因此可以学得user和item的最佳的嵌入表示的维度从而减少参数量。
尽管NAS(神经架构搜索)能够缓解构建模型的困难,但为了满足新的内存约束,往往还是需要重新训练,NAS搜索并训练得到的模型是针对一个特定的内存进行优化的。
边缘设备中一般只能获取到用户自己的嵌入表示,因此本文主要对item的embedding进行压缩,将完整的item embedding视为较小的embedding-block的串联,与组合嵌入的区别在于,每个item的embedding-block并不是共享的。组合嵌入表示可能存在一个候选的元嵌入集合,item的嵌入表示则是由这个元嵌入集合中的元嵌入组合而成,而本文的方法中的embedding-block并非是多个item共享的。
弹性embedding可以选择使用哪些embedding-block以及用多少embedding-block,从而控制item嵌入所占用的内存大小。
在所有item的嵌入空间进行搜索是不切实际的,因此考虑对item进行分组,同一group内的item共享embedding-block,从而缩小搜索空间,在训练时,增加一个多样性驱动的正则化,以鼓励embedding-block的多样性,提出了一种基于性能估计的进化搜索方法。为了加快搜索,在确定分配给每个group的embedding-block的数量时引入高斯先验,使得搜索函数在搜索重要/不重要的item时选取大/小维度的嵌入,同时保留其他group的嵌入维度。
多臂老虎机可以看作是一组实分布$B={R_1,\dots,R_k}$,第i杆奖励服从分布$R_i$,${}$
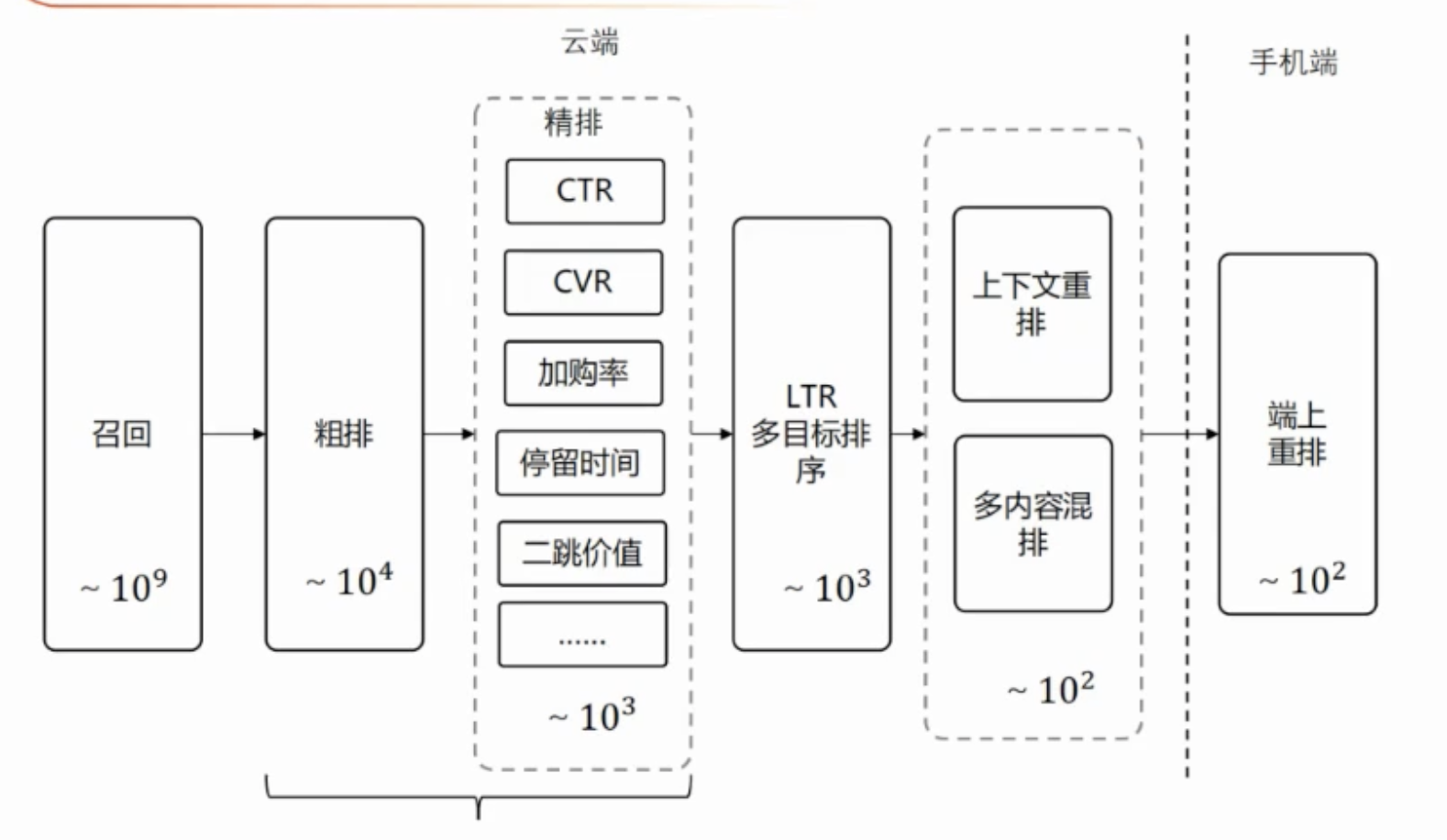
双塔内积,十万量级,用户侧在线计算,商品侧离线计算。
缺点:表达能力受限,内积模型无法加入交叉特征,部署一致性要求高。
天然bais:训练数据来源于曝光,而实际预测数据来源于召回。

样本选取
客户端区分,ios和android分端训练,很显然的道理,客户端界面不同,用户点击习惯也不同
样本不平衡
CTR正负样本比例约为1:100-1000,CVR则是1:10000甚至更低,解决方法是CTR模型正样本上采样10倍,CVR负样本下采样10倍,思想很好理解,CVR正负样本比例相差太大,正样本上采样效果自然不如负样本下采样
FM难以捕捉用户侧和广告侧稀疏特征的相关性,只有二阶特征组合,非线性表达能力不足,对于连续特征效果较差。
DGL安装脚本
1 | /bin/bash |
ParMETIS安装脚本
1 | /bin/bash |
bvar是多线程环境下的计数器类库,利用thread local存储减少了cache bouncing
今天跟算法同学沟通需求,需要对之前写过的一个DS的接口进行改动,在改代码的过程中,突然发现DS初始化里的assert(!_initialized)检查写成了assert(_initialized)。
理论上,在进行该DS初始化时应当初始化失败,程序停止并报错,但之前测试和调用都是正常的。
因为之前写python写的比较多,对C++的各种细节理解并不深刻,因此并不清楚assert相关的细节,只当它是与python中的assert是相同的。
1 | // assert.h |
在网上查阅资料之后发现,在VC编译器中assert只在DEBUG模式下生效,在RELEASE模式下不会进行编译。
查看assert.h头文件,头文件中的注释很清楚的写着如果定义了NDEBUG,那assert不会做任何事,如果未定义NDEBUG且表达式的值为0,就会打印错误信息并终止程序。
接下来我们来看下assert的实现,可以看到assert()使用宏来实现的,当定义了NDEBUG时,宏将会替换为void(0),不会做任何事,若未定义NDEBUG,则宏会首先判断表达式expr是否为真,若为真则什么都不做,若为假则打印错误信息并终止程序。
__attribute__ ((__noreturn__))告知编译器,该函数不会返回。
__assert_fail()是一个二进制标准库的函数,将会终止程序,详见__assert_fail。
在我们的编译系统,采用CMake生成Makefile,并且利用conan来管理依赖库版本,默认情况下CMake将会采用RELEASE进行编译。
我们经常有如下场景,需要对某一个函数的返回值进行类型检查,若函数正常执行则返回true,否则返回false。当这个函数的正确执行与否与程序状态相关时,我们需要对其进行做如下检查:
1 | assert(func(args)); |
由于assert的原理,在Release模式下,assert(expr)将会被宏替换为void(0),因此func(args)的逻辑并不会执行。
1 | bool status = func(args); |
CMake是一个编译系统生成工具,而非编译系统。CMake能够生成编译系统的输入文件如Makefile,CMake本身支持Make/Ninja/Visual Studio/XCode等。
CMake是跨平台的,支持Linux、Windows、OSX等,同时也支持跨平台构建(编译器要支持跨平台才可以哦)。
CMake开始于1999/2000年,现代CMake开始于2014年的3.0版本,现代CMake有一个非常重要的概念,Everything is a (self-contained) target。
Everything that is needed to (successfully) build that target.
Everything that is needed to (successfully) use that target.
时刻牢记以下三句话。
1 | cmake_minimum_required(VERSION 3.5) |
1 | project(hello-world VERSION 1.0 |
1 | add_executable(one two.cpp three.h) |
one既是生成的可执行程序也是Target,后续为源文件列表和头文件列表,大多数情况下,头文件将会被忽略,只是为了让他们显示在IDE中。
1 | ## BUILD_SHARED_LIBS |
1 | target_include_directories(ont PUBLIC include) |
PUBLIC意味着所有链接到此目标的目标都需要包含include目录,PRIVATE表示只有当前target需要,依赖项不需要,INTERFACE表示只有依赖项许需要。
1 | add_library(another STATIC another.cpp another.h) |
target_include_directories指定了target包含的头文件路径。
target_link_libraries指定了target链接的库。
target_compile_options指定了taget的编译选项。
target由add_library()和add_executable()生成。
我们以如下工程目录介绍PUBLIC/PRIVATE/INTERFACE。
1 | cmake-test/ 工程主目录,main.c 调用 libhello-world.so |
其调用关系如下所示
1 | ├────libhello.so |
PRIVATE:生成libhello-world.so时,只在hello_world.c中包含了hello.h,libhello-world.so对外的头文件hello_world.h不包含hello.h,并且main.c不调用hello.c中的函数,那么应当用PRIVATE。
1 | target_link_libraries(hello-world PRIVATE hello) |
INTERFACE:生成libhello-world.so时,只在libhello-world.so对外的头文件hello_world.h包含hello.h,hello_world.c不包含hello.h即libhello-world.so不使用libhello.so提供的功能,只需要hello.h中定义的结构体/类等类型信息,但main.c需要调用hello.c中的函数即libhello.so中的函数,那么应当用INTERFACE。
1 | target_link_libraries(hello-world INTERFACE hello) |
PUBLIC:生成libhello-world.so时,在libhello-world.so对外的头文件hello_world.h包含hello.h,hello_world.c也包含hello.h即libhello-world.so使用libhello.so提供的功能,并且main.c需要调用hello.c中的函数即libhello.so中的函数,那么应当用PUBLIC。
1 | target_link_libraries(hello-world PUBLIC hello) |
着重理解依赖传递的概念,main.c依赖于libhello-world.so,libhello-world.so依赖于libhello.so和libworld.so,若main.c不调用libhello.so中的功能,则hello-world与hello之间采用PRIVATE。若main.c调用libhello.so中的函数,但libhello-world.so不调用,则用INTERFACE。若main.c和libhello-world.so都调用libhello.so的函数,则使用PUBLIC关键字。
可以参考C++继承中PRIVATE/PROTECTED/PUBLIC的概念1。
1 | set(VAR1 "local variable") |
1 | set(VAR2 |
命令行调用之后,会将该变量写入CMakeCache.txt,之后调用若不从命令行重新赋值,则会一直采用Cache中的值。
1 | mkdir build && cd build |
bool类型的变量常用OPTION表示,OPTION也可以看作cache变量的一种,所以会写进CMakeCache.txt。
1 | OPTION(VAR3 "description" OFF/ON) |
cmake的一些常见变量见官网2。
1 | set(ENV{variable_name} value) |
1 | set_property(TARGET TargetName PROPERTY CXX_STANDARD 11) |
1 | if(${variable}) |
1 | function(SIMPLE_FUNC) |
其他控制逻辑有NOT/TARGET/EXISTS/DEFINED/AND/OR/STREQUAL/MATCHES/VERSION_LESS/VERSION_LESS_EQUAL等。
1 | class Node { |
1 | class Edge { |
控制依赖边,其src_output/dst_output均为Graph::kControlSlot(-1),意味着控制依赖边不承载任何数据。
计算图的普通边承载Tensor,并使用TensorId标识,TensorId由二元组node_name:src_output唯一标识,其中node_name为边的前驱节点。src_output缺省为0,即node_name与node_name:0等价,
1 | class Graph { |
Graph是一个DAG,按照拓扑排序运行,若存在多个入度为0的节点,则并行运行。初始状态,有一个起始节点Source和终止节点Sink,普通节点的id必大于1。
Source和Sink之间有一个控制依赖边,保证计算图的执行始于Source,止于Sink。
grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep在一个或多个文件中搜索字符串模板,如果模板包括空格,则必须使用引号引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
shell中可以通过$?获取上一个命令的返回值。
1 | Usage: grep [OPTION]... PATTERN [FILE]... |
| -参数 | –参数 | 用途 |
|---|---|---|
| -a | –text | 搜索二进制数据 |
| -i |
1 | # 查看第一个提交 |
修改Makefile
1 | -LIBS= -lssl |
编译
1 | make |
init-db同现代git中的git init .,在当前目录初始化仓库。
.dircache。.dircache/objects。.dircache/objects下创建目录00~ff共256个目录。将工作区的修改提交到暂存区。
.dircache/index。根据sha1值查看暂存区中的objects文件内容。objects内容为压缩格式,基于zlib压缩算法。
temp_git_file_xxxx中。