1. Learning Elastic Embeddings for Customizing On-Device Recommenders(KDD2021)
Motivation
服务器通常有着固定的内存和性能,因此我们可以训练一个模型,找到能够内存和计算能力适配这个模型的机器即可。不同于在服务器上进行推荐,边缘计算的难点在于边缘设备的性能相差较大,智能设备的内存大小不一,不可能为每一个设备都训练一个模型。
由于隐私和网络延迟的原因,现在更倾向于在边缘设备而非云服务器上部署推荐服务。在边缘设备上构建推荐系统的常用做法是压缩嵌入表示。本文提出了一种轻量级训练范式,核心思想是为每个item构造一个弹性embedding,弹性embedding是自动搜索出的由一组embedding-block的拼接。提出了一种RULE(Recommendation with Universally Learned Elastic Embeddings)方法,为了增强embeding-block的表示,在学习embedding-block时迫使其趋向于多样化;然后设计了基于性能估计的渐进搜索方法,允许在任何内存限制下来学习有效的弹性embedding。
Background
为了实现基于边缘计算的推荐系统,受限于边缘设备的内存大小,模型的参数数量以及embedding的维度需要有所限制,大部分工作都是基于潜在因子模型(LFM)来进行的,例如矩阵分解。主要思路是将每个user和item表示成embedding,然后通过相似度计算或者网络结构来计算两者的匹配得分,由于存在大量的类别特征,因此LFM模型的主要参数是embedding而非模型weights和biases。因此大多数工作都是压缩embedding的维度从而减小模型的大小。
早期研究采用离散哈希将实值嵌入转换为二进制,以两者的汉明距离来衡量user和item的相似性,由于转换过程中的信息丢失,使得二进制编码的表示效果极差,远不如普通的矩阵分解。
目前主要的两种方法是基于组合嵌入和多维嵌入的方法。组合嵌入只有少量的元嵌入表示,user和item则表示成元嵌入的不同组合,而多维嵌入允许每个嵌入表示在训练过程中的维度不一致,因此可以学得user和item的最佳的嵌入表示的维度从而减少参数量。
尽管NAS(神经架构搜索)能够缓解构建模型的困难,但为了满足新的内存约束,往往还是需要重新训练,NAS搜索并训练得到的模型是针对一个特定的内存进行优化的。
Idea
边缘设备中一般只能获取到用户自己的嵌入表示,因此本文主要对item的embedding进行压缩,将完整的item embedding视为较小的embedding-block的串联,与组合嵌入的区别在于,每个item的embedding-block并不是共享的。组合嵌入表示可能存在一个候选的元嵌入集合,item的嵌入表示则是由这个元嵌入集合中的元嵌入组合而成,而本文的方法中的embedding-block并非是多个item共享的。
弹性embedding可以选择使用哪些embedding-block以及用多少embedding-block,从而控制item嵌入所占用的内存大小。
在所有item的嵌入空间进行搜索是不切实际的,因此考虑对item进行分组,同一group内的item共享embedding-block,从而缩小搜索空间,在训练时,增加一个多样性驱动的正则化,以鼓励embedding-block的多样性,提出了一种基于性能估计的进化搜索方法。为了加快搜索,在确定分配给每个group的embedding-block的数量时引入高斯先验,使得搜索函数在搜索重要/不重要的item时选取大/小维度的嵌入,同时保留其他group的嵌入维度。
2. Disposable Linear Bandits for Online Recommendations
多臂老虎机(Multi-Arms Bandits)
多臂老虎机可以看作是一组实分布$B={R_1,\dots,R_k}$,第i杆奖励服从分布$R_i$,${}$
阿里淘宝首猜 (长序列建模)
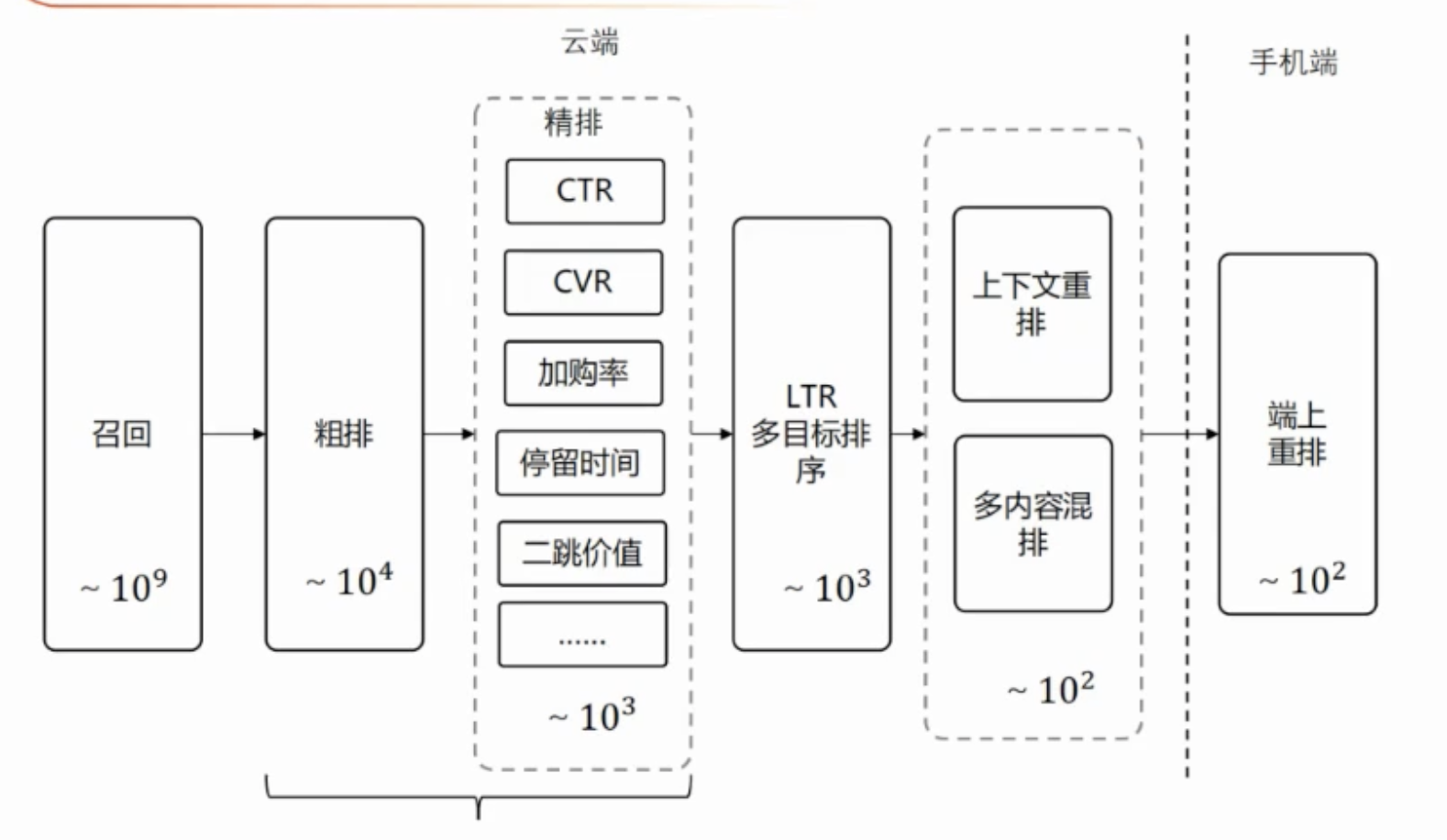
召回
粗排
双塔内积,十万量级,用户侧在线计算,商品侧离线计算。
缺点:表达能力受限,内积模型无法加入交叉特征,部署一致性要求高。
天然bais:训练数据来源于曝光,而实际预测数据来源于召回。
超长序列建模(两年,上万)
- 常规序列建模的方法依赖于交叉特征,使得双塔模型效果较差,序列建模适合用户行为session一致性较高的数据分布。
- 用户序列拉长能带来更好的效果,但transformer难以支持
- 粗排打分用户侧无法感知打分商品,无法在在线侧转为KV检索简化
解决方案
- 长期兴趣表征离线计算,用户侧增加离线计算单元
- 在线存储换计算,减少性能开销,(KV查user的长期兴趣表征)
建模思路
- 三塔模型
- 用户分类目长期行为表征(离线计算)
- 用户实时行为表征(在线计算)
- 商品表征(离线计算)
- 离线根据打分类目指定用户长期行为学习用户表征,端到端训练
- 在线部署拆图,用户侧加离线计算
精排
Target Attention 长序列建模局限性
- 计算开销大,限制了其对超长序列建模
- 本质上在历史行为序列中进行商品的相似性匹配,计算开销是内积,softmax之后关注Topk近邻。
- 基于向量检索的方法(SIM-soft)
- 近似检索,注重效率
- 离线架构索引,向量非端到端的学习
- 结构化属性倒排索引(SIM-hard,UBR4CTR,LALI)
- 思想是根据商品推荐类目体系离线构建倒排,在线查询
- 人工设计的结构化属性和点击率/转化率的预估目标有较大的gap
- 内容推荐、短视频推荐没有商品推荐中比较规范的类目结构化属性
基于simhash近似检索
- 降维思路
- 直接对emb降维,损失精度,效果差
- Local-sensitive hashing 一种高维向量空间快速检索k近邻的方法,通过多轮lsh提升精度,simHash是其二值化的特殊形式
- SimHash Attention
多轮LSH进行哈希,hash结果为0/1二进制位,采用汉明距离度量(count(xor)) - 优势
将内积attention转换为LSH attention,Query通过复杂内积运算对key检索的过程转化为高效的二进制运算。
ETA模型
网易云音乐广告系统
广告系统介绍
特点
- 听多于看
- 广告位分散,数据量适中
- 弱推荐
广告核心问题
- 广告买方:希望精准目标投放,降低成本,关注R(Relevane)O(Originality)I(Impact)投入产出比
- 广告媒介平台:点击转化高,价格高,关注收入最大化
解决办法
- 引入拍卖机制
- eCPM = pCTR Price 1000,每千次曝光可以获得的广告收入
CTR
浅层模型

样本选取
客户端区分,ios和android分端训练,很显然的道理,客户端界面不同,用户点击习惯也不同样本不平衡
CTR正负样本比例约为1:100-1000,CVR则是1:10000甚至更低,解决方法是CTR模型正样本上采样10倍,CVR负样本下采样10倍,思想很好理解,CVR正负样本比例相差太大,正样本上采样效果自然不如负样本下采样
FM模型
FM难以捕捉用户侧和广告侧稀疏特征的相关性,只有二阶特征组合,非线性表达能力不足,对于连续特征效果较差。
GBDT模型
- 需要对连续特征进行处理
- 特征深层交叉